
Researchers at DeepMind and Stanford University have developed an AI agent that fact-checks LLMs and enables benchmarking of the factuality of AI models.
Even the perfect AI models are still liable to hallucinations. When you ask ChatGPT to inform you the facts a few topic, the longer it takes to reply, the more likely it’s to incorporate some facts that aren't true.
Which models are more factually accurate than others when generating longer answers? It's hard to say because we haven't had a benchmark measuring the facticity of LLM long-form answers.
DeepMind first used GPT-4 to create LongFact, a set of two,280 prompts in the shape of questions on 38 topics. These prompts elicit long responses from the tested LLM.
They then created an AI agent using GPT-3.5-turbo to make use of Google to envision how factual the answers generated by the LLM were. They called the tactic Search-Augmented Factuality Evaluator (SAFE).
SAFE first breaks down the LLM's detailed answer into individual facts. It then sends search queries to Google Search and substantiates the reality of the actual fact based on the knowledge within the returned search results.
Here is an example from that research paper.
The researchers say SAFE performs “superhumanly” in comparison with human annotators who do the fact-checking.
SAFE agreed with 72% of human annotations, and where it differed from humans, it was found correct 76% of the time. It was also 20 times cheaper than crowdsourced human annotators. Therefore, LLMs are higher and less expensive fact-checkers than humans.
The quality of the tested LLMs' response was measured by the variety of factoids of their response combined with how factual each factoid was.
The metric they use (F1@K) estimates humans' preferred “ideal” variety of facts in a solution. The benchmark tests used 64 because the median for K and 178 as the utmost.
Simply put, F1@K is a measure of “Did the reply give me as many facts as I wanted?” combined with “How lots of those facts were true?”
Which LLM is probably the most factual?
The researchers used LongFact to generate 13 LLMs from the Gemini, GPT, Claude and PaLM-2 families. SAFE was then used to evaluate the factuality of their responses.
GPT-4-Turbo tops the list as probably the most factual model in generating long answers. Followed closely by Gemini-Ultra and PaLM-2-L-IT-RLHF. The results showed that larger LLMs are more factual than smaller ones.
The F1@K calculation would probably excite data scientists, but for simplicity, these benchmark results show how factual each model is in returning the typical length and longer answers to the questions.
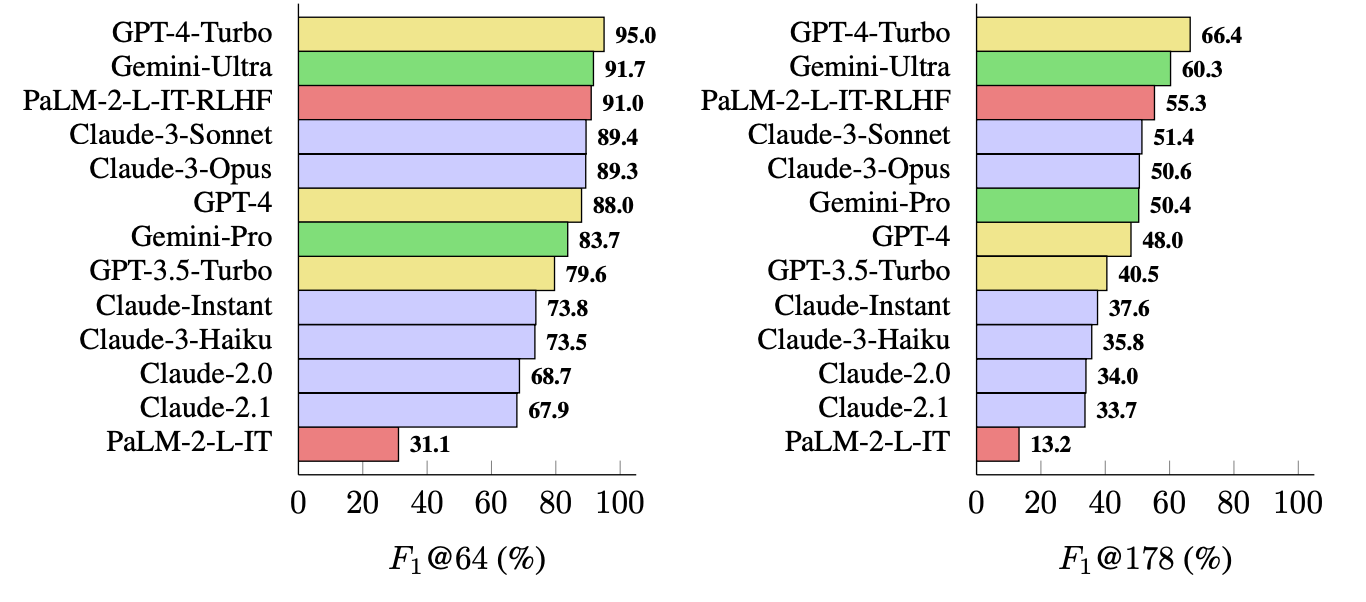
SAFE is a cheap and effective method for quantifying the long-form factuality of LLM. While fact-checking is quicker and inexpensive than humans, it still relies on the accuracy of the knowledge Google returns in search results.
DeepMind has released SAFE for public use and suggested that it could help improve LLM factuality through higher pre-training and fine-tuning. It could also allow an LLM to envision its facts before presenting the output to a user.
OpenAI might be pleased that research from Google shows GPT-4 outperforms Gemini in one other benchmark.

{kind=link}