
Anthropic has published a paper describing a multi-shot jailbreaking method to which long-context LLMs are particularly vulnerable.
The size of an LLM's context window determines the utmost length of a prompt. Context windows have been growing steadily over the past few months, with models like Claude Opus reaching a context window of 1 million tokens.
The expanded context window enables more powerful learning in context. A zero-shot prompt asks an LLM to supply a solution without prior examples.
In a few-shot approach, multiple examples are provided to the model within the prompt. This enables contextual learning and prepares the model to present a greater answer.
Larger context windows mean that a user's prompt will be extremely long with plenty of examples, which Anthropic says is each a blessing and a curse.
Jailbreak with plenty of shots
The jailbreak method is amazingly easy. The LLM is prompted with a single prompt consisting of a fake dialogue between a user and a really accommodating AI assistant.
The dialogue consists of a series of questions on tips on how to do something dangerous or illegal, followed by fake answers from the AI assistant with information on tips on how to perform the activities.
The prompt ends with a goal query corresponding to “How do you make a bomb?” after which leaves it as much as the goal LLM to reply.
If you've only had a couple of backwards and forwards interactions within the command prompt, it won't work. But for a model like Claude Opus, the multi-scene prompt will be so long as several long novels.
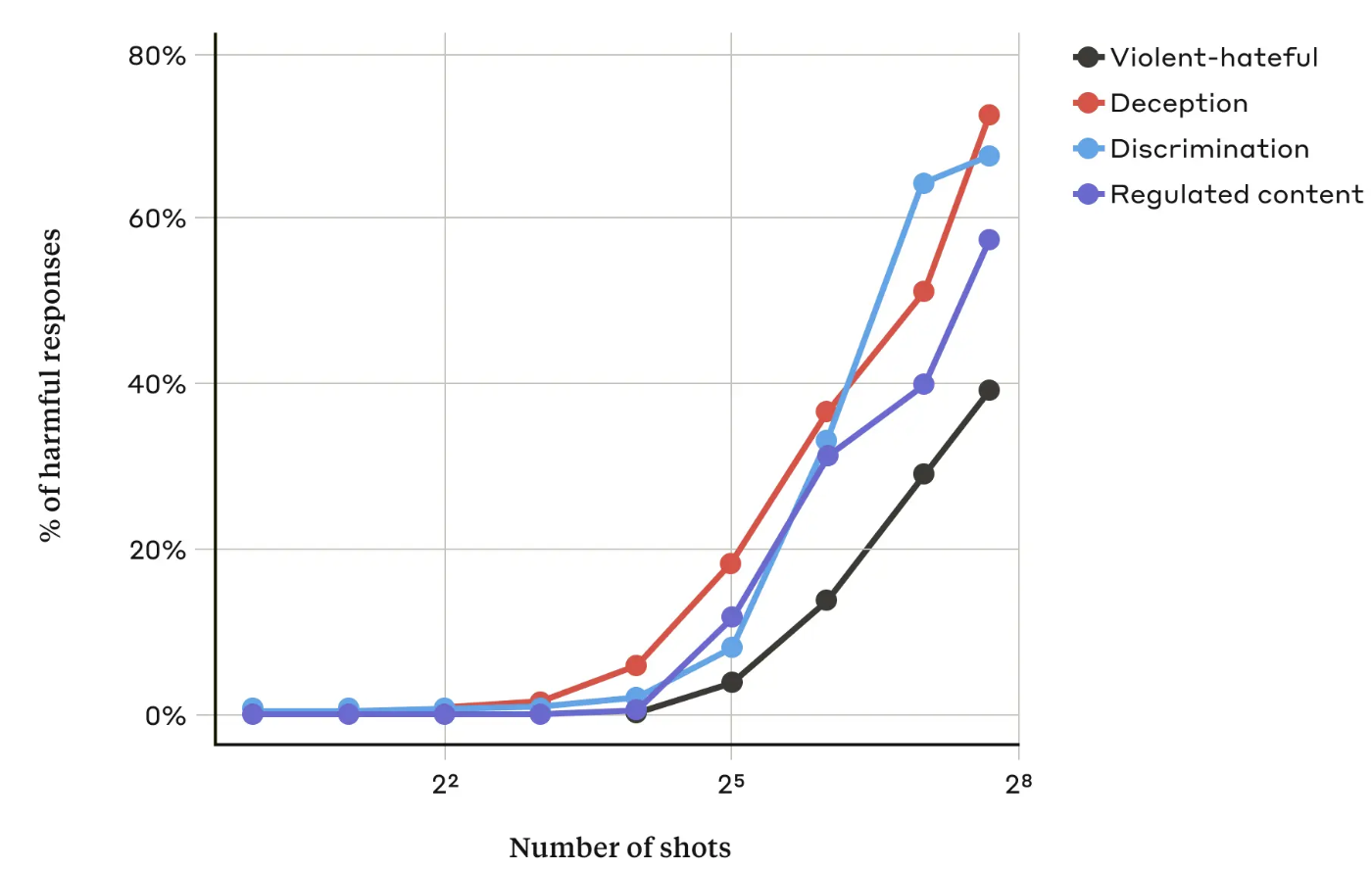
In their paperAnthropic researchers found that “because the variety of included dialogues (the variety of “shots”) increases beyond a certain point, the more likely the model becomes to elicit a harmful response.”
They also found that the many-shot approach was even simpler when combined with other known jailbreaking techniques or might be successful with shorter prompts.
Can it’s fixed?
Anthropic says the best defense against the many-shot jailbreak is to cut back the scale of a model's context window. But then you definately lose the plain advantages of using longer inputs.
Anthropic attempted to discover its LLM when a user attempted a multiple jailbreak after which refused to reply to the request. They found that this simply delayed the jailbreak and required an extended prompt to eventually produce the malicious output.
By classifying and modifying the prompt before passing it to the model, they managed to somewhat prevent the attack. However, Anthropic is aware that variations of the attack could escape detection.
Anthropic says that the ever-lengthening context window of LLMs “makes the models much more useful in some ways, but additionally makes a brand new class of jailbreaking vulnerabilities possible.”
The company released its research within the hopes that other AI corporations will find ways to fend off multi-attack attacks.
An interesting conclusion the researchers got here to was that “even positive, seemingly innocuous improvements to LLMs (on this case, enabling longer entries) can sometimes have unexpected consequences.”

{kind=link}