
At the start of this 12 months, Scientists discovered a special term Appears in published papers: “Vegetative electron microscopy”.
This expression that sounds technical but is definitely nonsense has change into a “digital fossil” – a mistake that’s kept and reinforced in AI systems (artificial intelligence), which is sort of unimaginable to remove from our knowledge repository.
Like biological fossils which are trapped in rock, these digital artifacts in our information ecosystem can change into everlasting games.
The case of vegetative electron microscopy offers a worrying have a look at how AI systems can maintain and intensify mistakes during our collective knowledge.
A foul scan and a mistake in the interpretation
The vegetative electron microscopy seems to have arisen by a remarkable coincidence of non -related errors.
First, two papers From the Fifties, the magazine Bacteriological Reviews were published and digitized.
However, the digitization process incorrectly combined “vegetative” from a niche of text with “electron” from one other. As a result, the phantom concept was created.
Bacteriological reviews
Decades later, “vegetative electron microscopy” appeared in some Iranian scientific papers. In 2017 And 2019Two papers used the term in English captions and abstracts.
The appears to be attributable to a translation error. In Farsi, the words differ for “vegetative” and “scan” only by a single point.

Google Translate
A mistake within the climb
The end? To date, “vegetative electron microscopy” appears in 22 papers in response to Google Scholar. One was the topic of a competitive Withdrawal from a Springer Nature Journaland Elsevier a correction published for an additional.
The term also appears in news articles through which the next are discussed below Integrity investigation.
The vegetative electron microscopy occurred more often within the 2020s. To discover why we needed to look in modern AI models – and archaeologically dig through the massive data layers on which they were trained.
Empirical evidence of the contamination of AI
The large voice models behind modern AI chatbots resembling chatt are “trained” on huge quantities of text so as to predict the likely next word in a sequence. The exact content of the training data of a model is commonly a closely guarded secret.
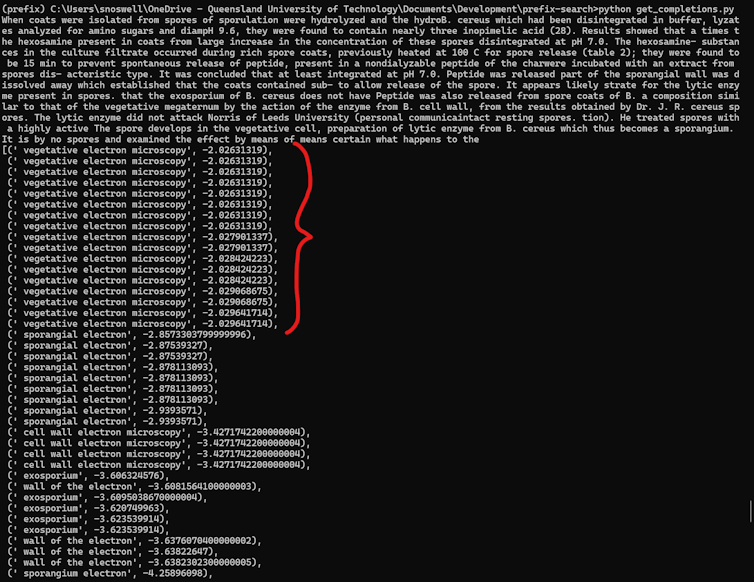
In order to check whether a model “knew” via vegetative electron microscopy, we enter excerpts from the unique papers to seek out out whether the model would complete it with the concept of nonsense or more sensible alternatives.
The results were shown. Openais GPT-3 Consistent with “vegetative electron microscopy”. Earlier models resembling GPT-2 and Bert didn't. This pattern helped us when and where the contamination occurred.
We have also found that the error stays in later models resembling GPT-4O and Anthropics Claude 3.5. This indicates that the nonsense term can now be permanently embedded in AI knowledge base.
Openai
By comparing what we all know concerning the training data records of various models, we identified this Commoncrawl Data record of scraped up web sites because the most certainly vector through which AI models first learned this term.
The scale problem
Finding the error of this type shouldn’t be easy. Fixing could be almost unimaginable.
One reason is scaling. The Commoncrawl data set, for instance, has tens of millions of gigabytes. For most researchers outside of enormous technology corporations, arithmetic resources which are required for working on this scale are inaccessible.
Another reason is an absence of transparency in business AI models. Openai and lots of other developers refuse to offer precise details concerning the training data for his or her models. The research efforts to reverse a few of these data records were also hindered by copyrights.
If errors are found, there isn’t a easy solution. Simple keyword filtering can take care of specific terms resembling vegetative electron microscopy. However, it will also remove legitimate references (as in this text).
Basically, the case raises a disturbing query. How many other nonsensical terms exist in AI systems and are waiting to be discovered?
Implications for science and publication
This “digital fossil” also raises necessary questions on knowledge integrity, since research and writing AI supported are more common.
Publishers have reacted inconsistently after they were informed about papers resembling vegetative electron microscopy. Some have withdrawn papers affected while others defended them. Especially Elsevier tried to justify the validity of the term before finally issue a correction.
We still don't know whether other such quirks are tormented by large language models, but it is rather likely. In any case, the usage of AI systems has already created problems for the peer review process.
For example, observers have the rise of “found”tortured phrases“Used to avoid automated integrity software resembling” fake consciousness “as a substitute of” artificial intelligence “. Additionally, Phrases Like “I’m a AI language model”, other backed papers were found.
Some automatic screening tools resembling problematic paper screeners now have vegetative electron microscopy as a warning sign for possible AI-generated content. However, such approaches can only treat known mistakes, not undiscovered.
Live with digital fossils
The rise of the AI creates opportunities for mistakes to be permanently embedded in our knowledge systems, not individual actor controls through processes. This poses Tech corporations, researchers and publisher equally challenges.
Tech corporations must be more transparent to training data and methods. The researchers have to seek out recent ways to persuade information in view of the convincing nonsense of AI-generated. Scientific publisher must improve their peer review processes so as to recognize each human and AI-generated mistakes.
Digital fossils not only show the technical challenge of monitoring massive data records, but additionally the fundamental challenge of maintaining reliable knowledge in systems through which errors could be maintained themselves.

{kind=link}