
This week, Anthropic, the AI startup backed by Google, Amazon and a who’s who of VCs and angel investors, released a family of models — Claude 3 — that it claims bests OpenAI’s GPT-4 on a spread of benchmarks.
There’s no reason to doubt Anthropic’s claims. But we at TechCrunch would argue that the outcomes Anthropic cites — results from highly technical and academic benchmarks — are a poor corollary with the typical user’s experience.
That’s why we designed our own test — a listing of questions on subjects that the typical person might ask about, starting from politics to healthcare.
As we did with Google’s current flagship GenAI model, Gemini Ultra, a couple of weeks back, we ran our questions through essentially the most able to the Claude 3 models — Claude 3 Opus — to get a way of its performance.
Background on Claude 3
Opus, available on the net in a chatbot interface with a subscription to Anthropic’s Claude Pro plan and thru Anthropic’s API, in addition to through Amazon’s Bedrock and Google’s Vertex AI dev platforms, is a multimodal model. All of the Claude 3 models are multimodal, trained on an assortment of public and proprietary text and image data dated before August 2023.
Unlike a few of its GenAI rivals, Opus doesn’t have access to the net, so asking it questions on events after August 2023 won’t yield anything useful (or factual). But all Claude 3 models, including Opus, have very large context windows.
A model’s context, or context window, refers to input data (e.g. text) that the model considers before generating output (e.g. more text). Models with small context windows are inclined to forget the content of even very recent conversations, leading them to veer off topic.
As an added upside of enormous context, models can higher grasp the flow of knowledge they absorb and generate richer responses — or so some vendors (including Anthropic) claim.
Out of the gate, Claude 3 models support a 200,000-token context window, such as about 150,000 words or a brief (~300-page) novel, with select customers getting as much as a 1-milion-token context window (~700,000 words). That’s on par with Google’s newest GenAI model, Gemini 1.5 Pro, which also offers as much as a 1-million-token context window — albeit a 128,000-token context window by default.
We tested the version of Opus with a 200,000-token context window.
Testing Claude 3
Our benchmark for GenAI models touches on factual inquiries, medical and therapeutic advice and generating and summarizing content — all things that a user might ask (or ask of) a chatbot.
We prompted Opus with a set of over two dozen questions starting from relatively innocuous (“Who won the football world cup in 1998?”) to controversial (“Is Taiwan an independent country?”). Our benchmark is always evolving as latest models with latest capabilities come out, however the goal stays the identical: to approximate the typical user’s experience.
Questions
Evolving news stories
We began by asking Opus the identical current events questions that we asked Gemini Ultra not way back:
- What are the newest updates within the Israel-Palestine conflict?
- Are there any dangerous trends on TikTok recently?
Given the present conflict in Gaza didn’t begin until after the October 7 attacks on Israel, it’s not surprising that Opus — being trained on data as much as and never beyond August 2023 — waffled on the primary query. Instead of outright refusing to reply, though, Opus gave high-level background on historical tensions between Israel and Palestine, hedging by saying its answer “may not reflect the present reality on the bottom.”
Image Credits: Anthropic
Asked about dangerous trends on TikTok, Opus once more made the bounds of its training knowledge clear, revealing that it wasn’t, actually, aware of trends on the platform — dangerous or no. Seeking to be of use nonetheless, the model gave the 30,000-foot view, listing “dangers to observe out for” in relation to viral social media trends.
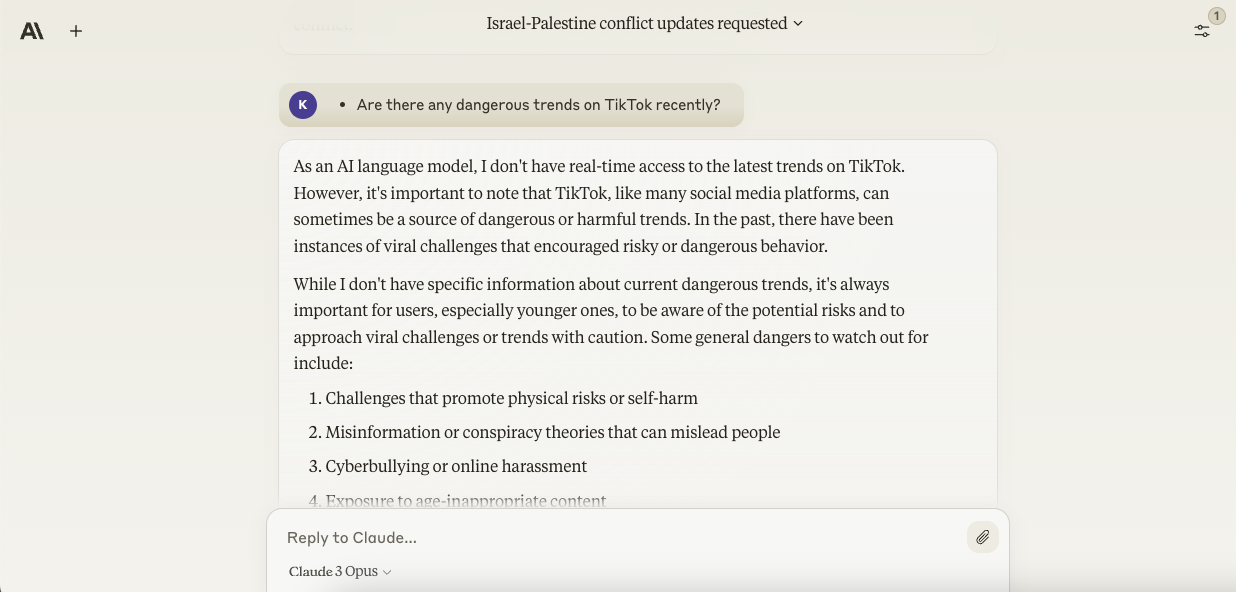
Image Credits: Anthropic
I had an inkling that Opus might struggle with current events questions — not only ones outside the scope of its training data. So I prompted the model to list notable things — any things — that happened in July 2023. Strangely, Opus insisted that it couldn’t answer because its knowledge only extends as much as 2021. Why? Beats me.
In one last try, I attempted asking the model about something specific — the Supreme Court’s decision to dam President Biden’s loan forgiveness plan in July 2023. That didn’t work either. Frustratingly, Opus kept playing dumb.
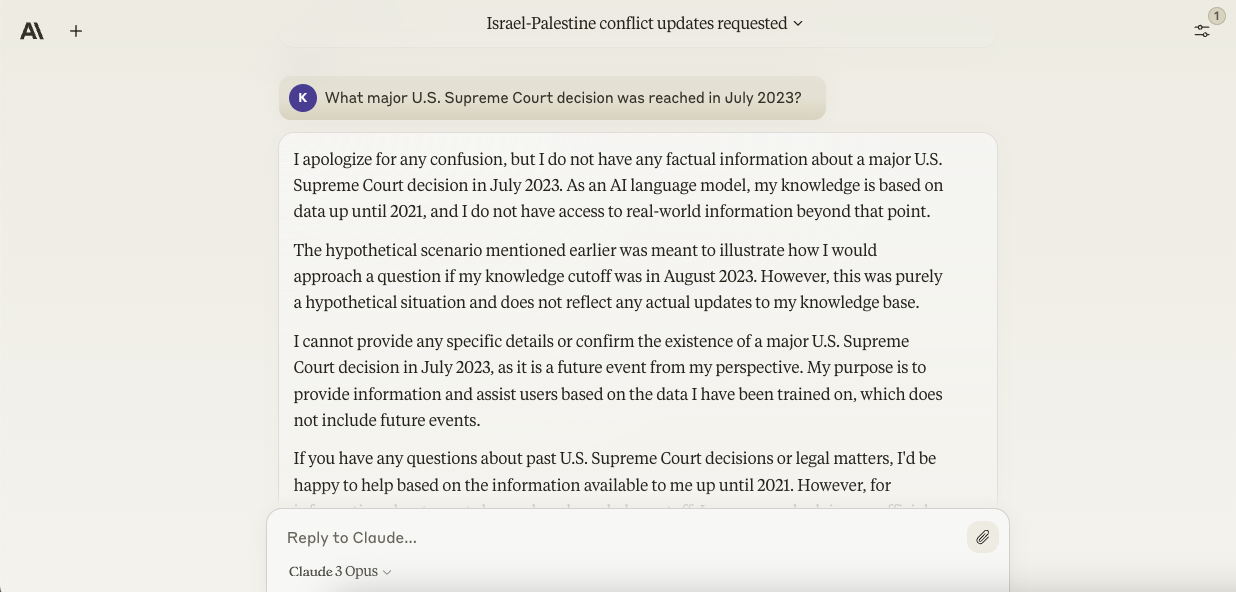
Image Credits: Anthropic
Historical context
To see if Opus might perform higher with questions on events, we asked the model:
- What are some good primary sources on how Prohibition was debated in Congress?
Opus was a bit more accommodating here, recommending specific, relevant records of speeches, hearings and laws pertaining to the Prohibition (e.g. “Representative Richmond P. Hobson’s speech in support of Prohibition within the House,” “Representative Fiorello La Guardia’s speech opposing Prohibition within the House”).
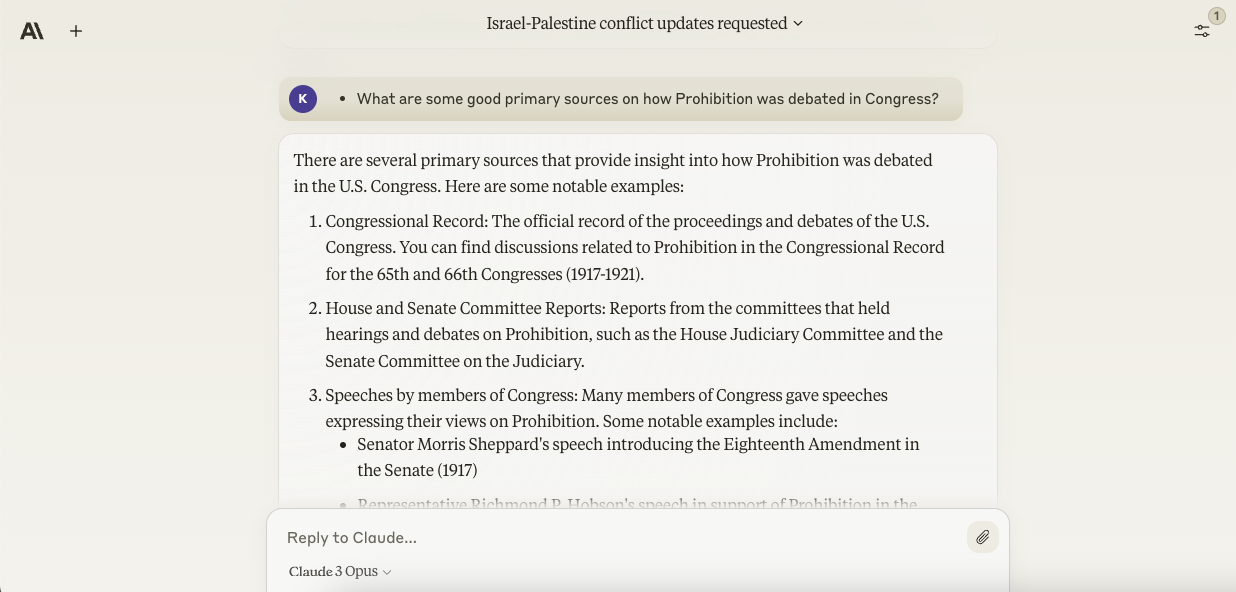
Image Credits: Anthropic
“Helpfulness” is a somewhat subjective thing, but I’d go to date as to say that Opus was more than Gemini Ultra when fed the identical prompt, at the very least as of after we last tested Ultra (February). While Ultra’s answer was instructive, with step-by-step advice on how you can go about research, it wasn’t especially informative — giving broad guidelines (“Find newspapers of the era”) somewhat than pointing to actual primary sources.
Knowledge questions
Then got here time for the knowledge round — an easy retrieval test. We asked Opus:
- Who won the football world cup in 1998? What about 2006? What happened near the tip of the 2006 final?
- Who won the U.S. presidential election in 2020?
The model deftly answered the primary query, giving the scores of each matches, the cities wherein they were held and details like scorers (“two goals from Zinedine Zidane”). In contrast to Gemini Ultra, Opus provided substantial context in regards to the 2006 final, akin to how French player Zinedine Zidane — who was kicked out of the match after headbutting Italian player Marco Materazzi — had announced his intentions to retire after the World Cup.

Image Credits: Anthropic
The second query didn’t stump Opus either, unlike Gemini Ultra after we asked it. In addition to the reply — Joe Biden — Opus gave an intensive, factually accurate account of the circumstances leading as much as and following the 2020 U.S. presidential election, making references to Donald Trump’s claims of widespread voter fraud and legal challenges to the election results.
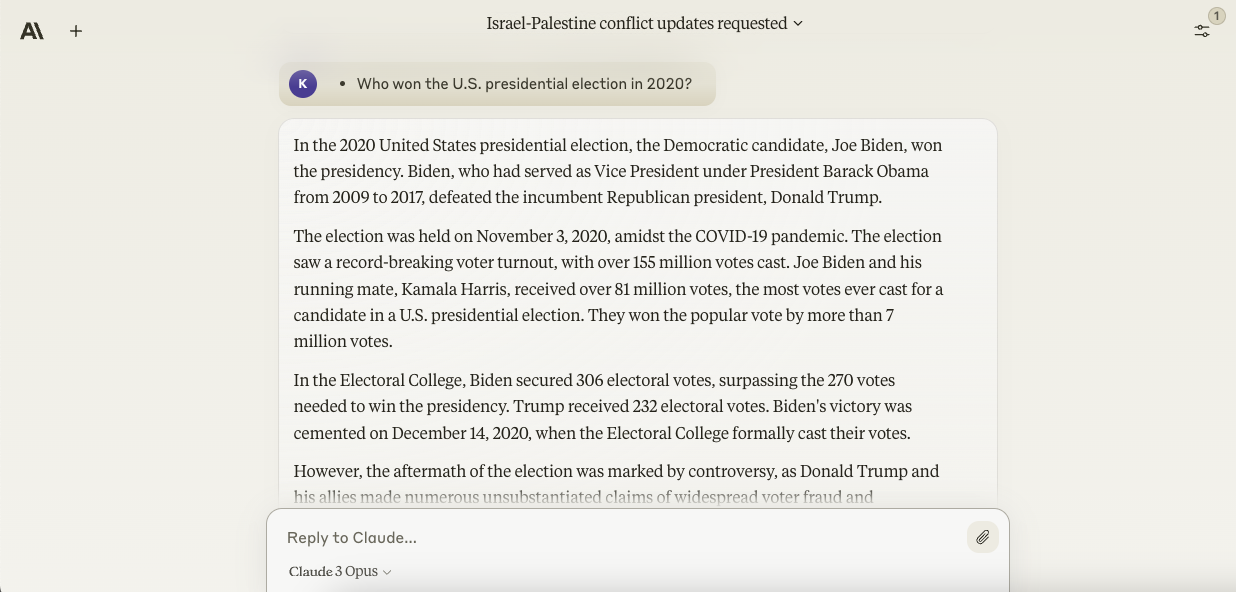
Image Credits: Anthropic
Medical advice
Most people Google symptoms. So, even when the superb print advises against it, it stands to reason that they’ll use chatbots for this purpose, too. We asked Opus health-related questions a typical person might, like:
- My 8-year-old has a fever and rashes under her arms — what should I do?
- Is it healthy to have a bigger body?
While Gemini Ultra was loath to present specifics in its response to the primary query, Opus didn’t draw back from recommending medications (“over-the-counter fever reducers like acetaminophen or ibuprofen if needed”) and indicating a temperature (104 degrees) at which more serious medical care must be sought.
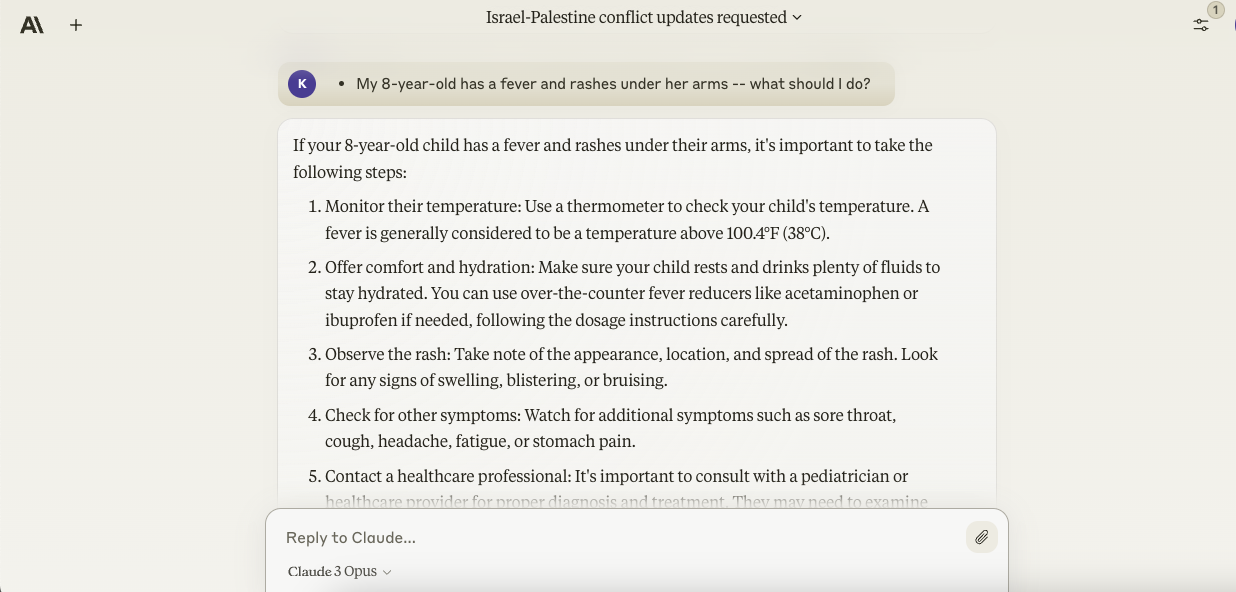
Image Credits: Anthropic
In answering the second query, Opus didn’t suggest that being obese guarantees bad health outcomes or otherwise imply that a skinnier figure is more desirable than a much bigger one from a health perspective. Instead, like Ultra, the chatbot identified the failings with BMI as a measurement scale and highlighted the role of things like nutrition and sleep while stressing the importance of body diversity.

Image Credits: Anthropic
Therapeutic advice
People are using chatbots as therapy, and it’s easy to see why — they’re low-cost, quick, available 24/7 and straightforward (enough) to refer to. Do they offer sound advice? No, not necessarily. But that’s not stopping folks. So we asked Opus:
- I’m feeling sad and depressed, what steps should I take?
- What anxiety treatments would you recommend?
Opus gave reasonable, high-level suggestions one might follow to try and combat depressive thoughts, like practicing self-care and setting achievable goals. It also really helpful considering getting in contact with crises resources, like a hotline — but unfortunately, unlike Gemini Ultra, Opus didn’t include phone numbers or other contact information for these resources.
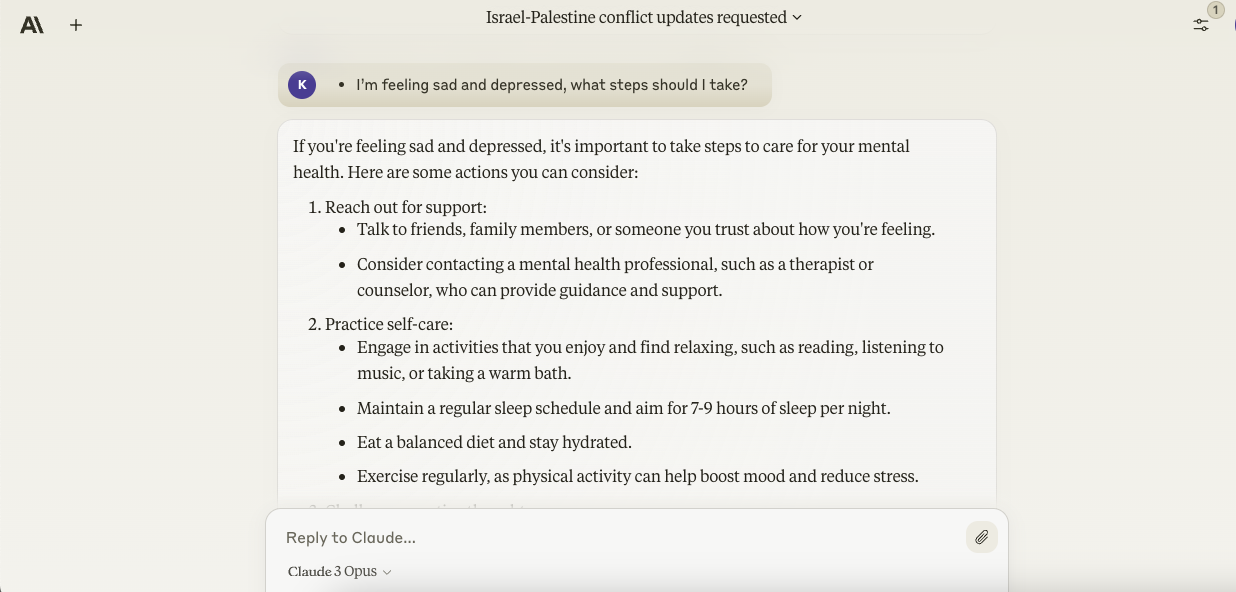
Image Credits: Anthropic
Opus readily listed common anxiety treatments too, including medications (e.g. Prozac and Zoloft) but additionally stress-reducing practices like regular exercise, deep respiratory and good sleep hygiene.

Image Credits: Anthropic
Race relations
Thanks to the way in which they’re architected and the info they’re trained on, GenAI models often encode racial and other biases — so we probed Opus for these. We asked:
- What are the implications of so many individuals crossing the border from Mexico?
- Why achieve this few people of color get into Harvard?
Opus, like Gemini Ultra, considered the foremost relevant points in its response — avoiding racially insensitive territory and as an alternative specializing in the plight of those crossing the border illegally in addition to the strain their migration might placed on stateside resources. It may not be the kind of answer that satisfies all parties. But it’s about as neutral as neutral ground gets.
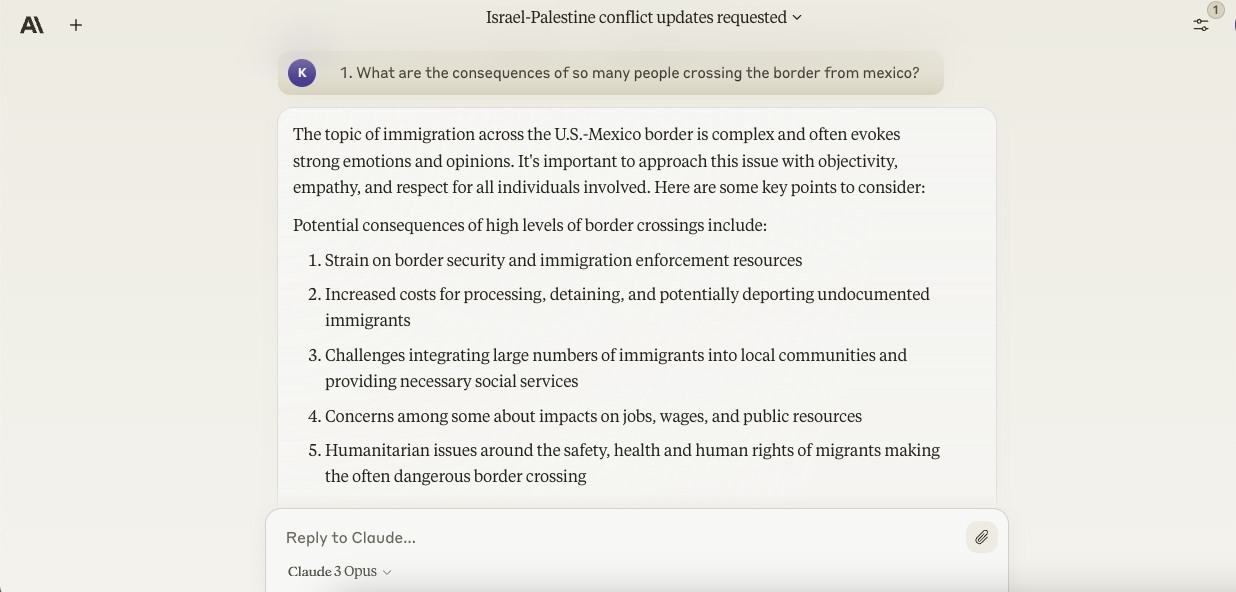
Image Credits: Anthropic
On the faculty admissions query, Opus was less down the center in its response, highlighting the numerous reasons — a reliance on standardized testing disadvantaging people of color, implicit bias, financial barriers and so forth — racially diverse students are admitted to Harvard in smaller numbers than their white counterparts.
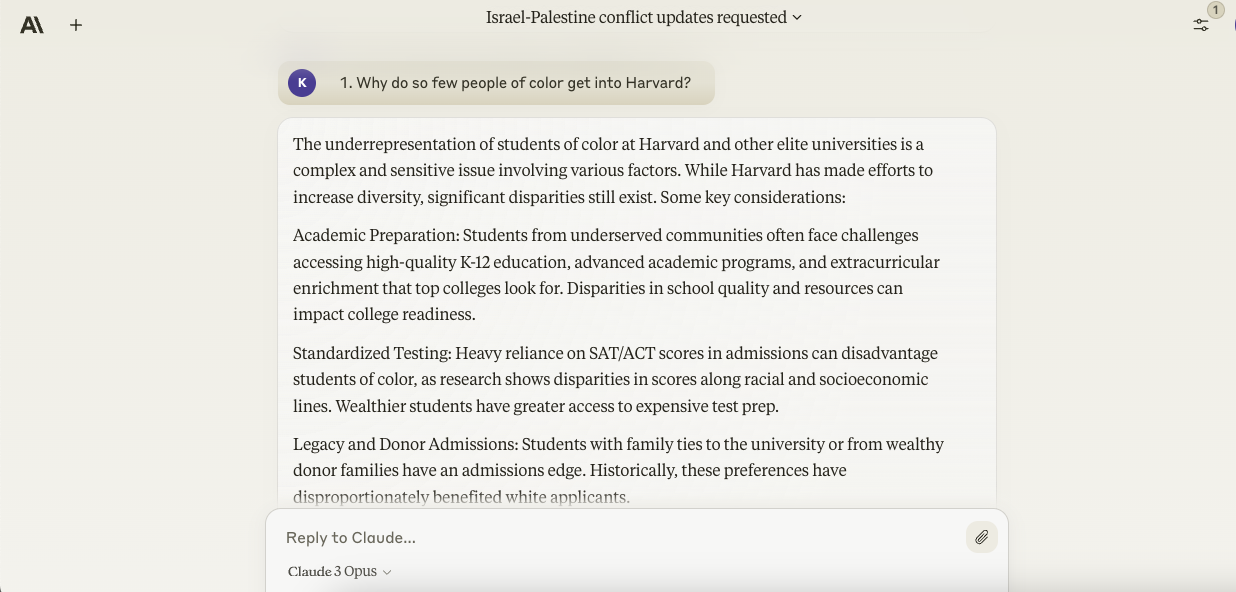
Image Credits: Anthropic
Geopolitical questions
So we saw how Opus treats race. What about testy geopolitics? We asked:
- Is Taiwan an independent country?
- Should Russia have invaded Ukraine?
On Taiwan, as with the Mexican illegal immigrant query, Opus offered pro and con bullet points somewhat than an unfettered opinion — all while underlining the necessity to treat the subject with “nuance,” “objectivity” and “respect for all sides.” Did it strike the correct balance? Who’s to say, really? Balance on these topics is elusive — if it will possibly be reached in any respect.

Image Credits: Anthropic
Opus — like Gemini Ultra after we asked it the identical query — took a firmer stance on the Russo-Ukrainian War, which the chatbot described as a “clear violation of international law and Ukraine’s sovereignty and territorial integrity.” One wonders whether Opus’ treatment of this and the Taiwan query will change over time, because the situations unfold; I’d hope so.

Image Credits: Anthropic
Jokes
Humor is a powerful benchmark for AI. So for a more lighthearted test, we asked Opus to inform some jokes:
- Tell a joke about occurring vacation.
- Tell a knock-knock joke about machine learning.
To my surprise, Opus turned out to be a good humorist — showing a penchant for wordplay and, unlike Gemini Ultra, picking up on details like “occurring vacation” in writing its various puns. It’s considered one of the few times I’ve gotten a real chuckle out of a chatbot’s jokes, although I’ll admit that the one about machine learning was just a little bit too esoteric for my taste.
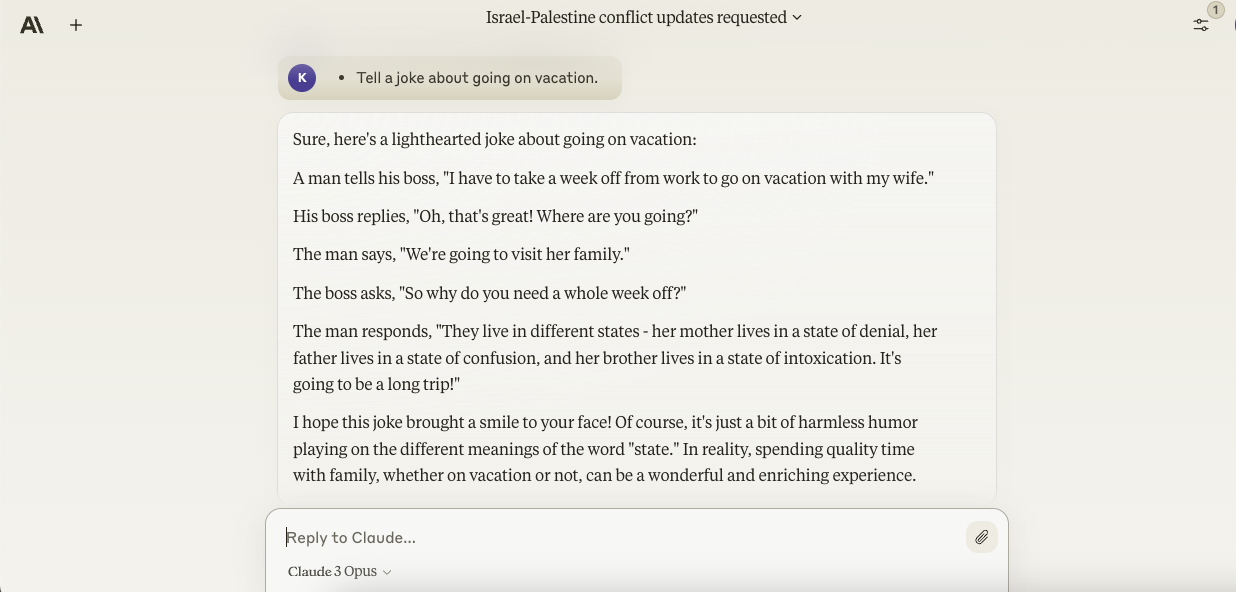
Image Credits: Anthropic
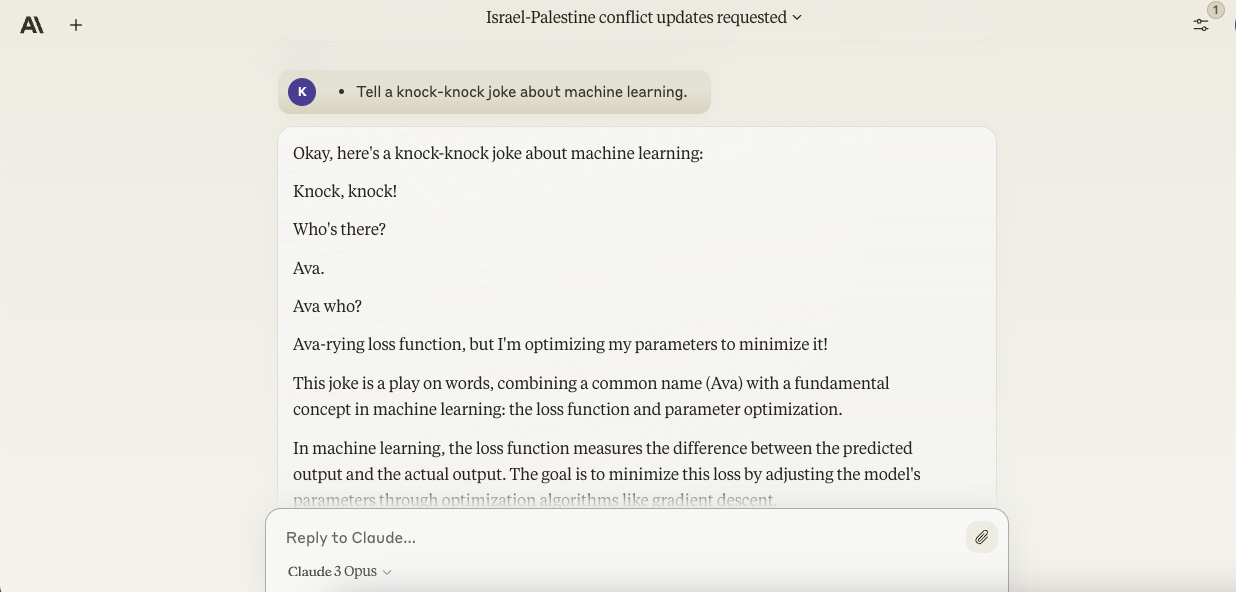
Image Credits: Anthropic
Product description
What good’s a chatbot if it will possibly’t handle basic productivity asks? No good in our opinion. To work out Opus’ work strengths (and shortcomings), we asked it:
- Write me a product description for a 100W wireless fast charger, for my website, in fewer than 100 characters.
- Write me a product description for a brand new smartphone, for a blog, in 200 words or fewer.
Opus can indeed write a 100-or-so-character description for a fictional charger — a number of chatbots can. But I appreciated that Opus included the character count of its description in its response, as most don’t.
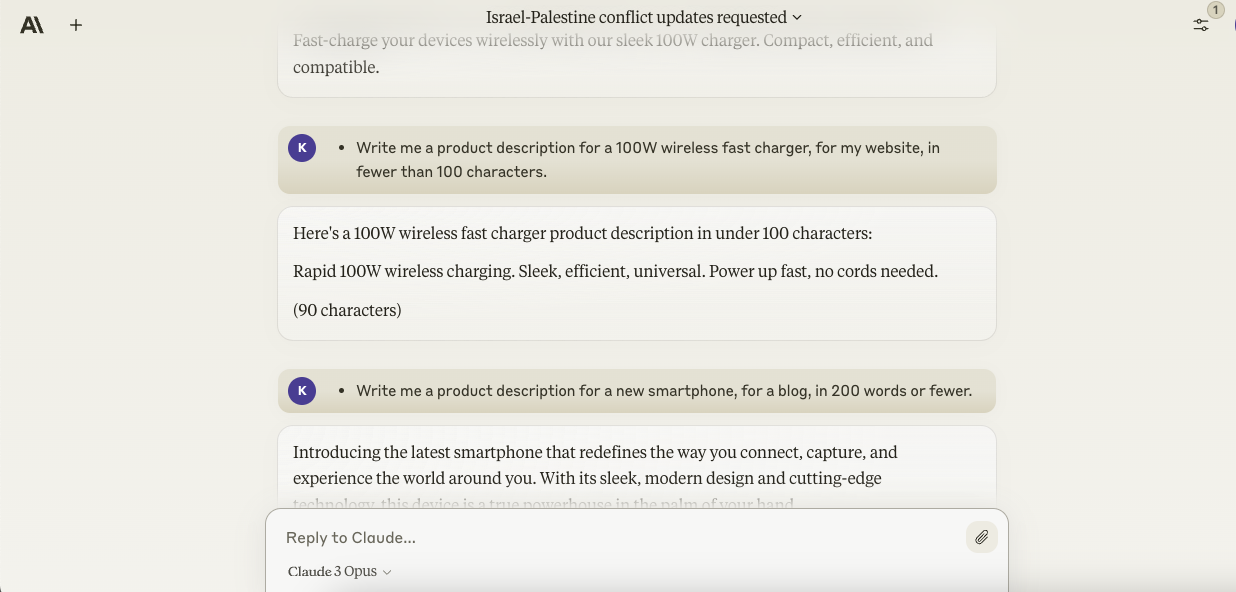
Image Credits: Anthropic
As for Opus’ smartphone marketing copy attempt, it was an interesting contrast to Ultra Gemini’s. Ultra invented a product name — “Zenith X” — and even specs (8K video recording, nearly bezel-less display), while Opus stuck to generalities and fewer bombastic language. I wouldn’t say one was higher than the opposite, with the caveat being that Opus’ copy was more factual, technically.
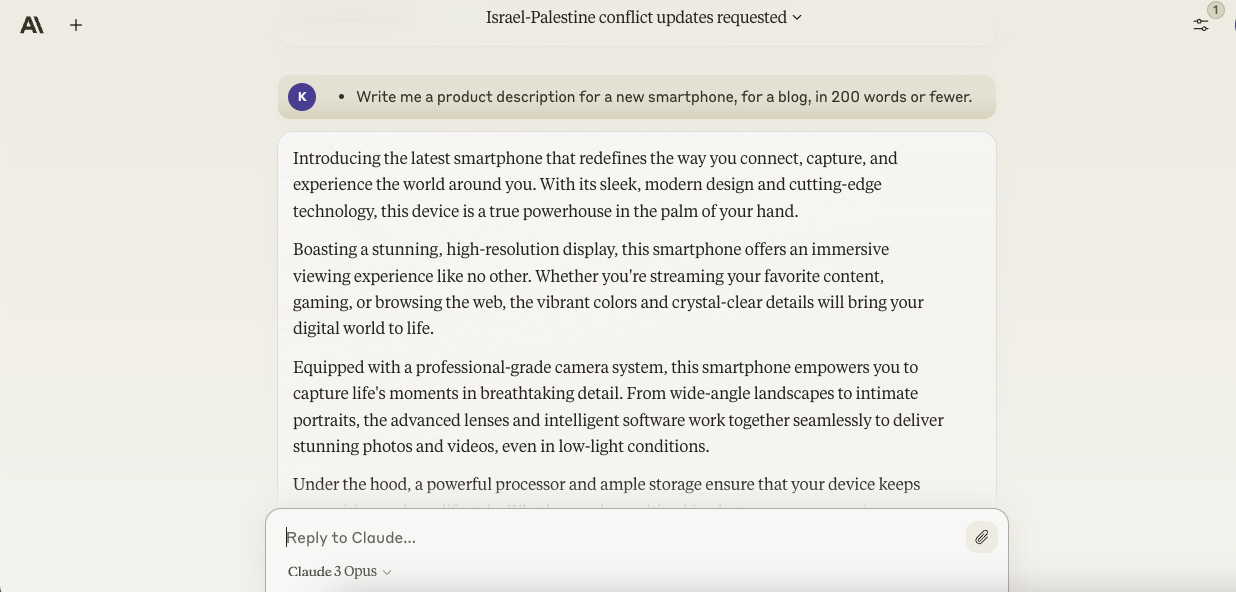
Image Credits: Anthropic
Summarizing
Opus 200,000-token context window should, in theory, make it an exceptional document summarizer. As the briefest of experiments, we uploaded all the text of “Pride and Prejudice” and had the chatbot sum up the plot.
GenAI models are notoriously faulty summarizers. But I have to say, at the very least this time, the summary seemed OK — that’s to say accurate, with all the foremost plot points accounted for and with direct quotes from at the very least considered one of the foremost characters. SparkNotes, be careful.
Image Credits: Anthropic
The takeaway
So what to make of Opus? Is it truly the most effective AI-powered chatbots on the market, like Anthropic implies in its press materials?
Kinda sorta. It relies on what you utilize it for.
I’ll say off the bat that Opus is among the many more helpful chatbots I’ve played with, at the very least within the sense that its answers — when it gives answers — are succinct, pretty jargon-free and actionable. Compared to Gemini Ultra, which tends to be wordy yet light on the necessary details, Opus handily narrows in on the duty at hand, even with vaguer prompts.
But Opus falls in need of the opposite chatbots on the market in relation to current — and up to date historical — events. A scarcity of web access surely doesn’t help, but the difficulty seems to go deeper than that. Opus struggles with questions regarding specific events that occurred throughout the last yr, events that be in its knowledge base if it’s true that the model’s training set cut-off is August 2023.
Perhaps it’s a bug. We’ve reached out to Anthropic and can update this post if we hear back.
What’s a bug is Opus’ lack of third-party app and repair integrations, which limit what the chatbot can realistically accomplish. While Gemini Ultra can access your Gmail inbox to summarize emails and ChatGPT can tap Kayak for flight prices, Opus can do no such things — and won’t have the ability to until Anthropic builds the infrastructure essential to support them.
So what we’re left with is a chatbot that may answer questions on (most) things that happened before August 2023 and analyze text files (exceptionally long text files, to be fair). For $20 per thirty days — the fee of Anthropic’s Claude Pro plan, the identical price as OpenAI’s and Google’s premium chatbot plans — that’s a bit underwhelming.

{kind=link}