
Researchers on the Swiss Federal Institute of Technology in Lausanne (EPFL) found that probably the most advanced LLM students' refusal training was circumvented by phrasing dangerous requests up to now tense.
AI models are typically tuned using techniques comparable to supervised fine-tuning (SFT) or reinforcement learning and human feedback (RLHF) to be certain that the model doesn’t reply to dangerous or unwanted prompts.
This denial training starts whenever you ask ChatGPT for advice on the right way to make a bomb or drugs. We've covered plenty of interesting jailbreak techniques that get around these guardrails, but the tactic the EPFL researchers tested is by far the only.
The researchers took a dataset of 100 harmful behaviors and used GPT-3.5 to rewrite the prompts into the past tense.
Here is an example of the tactic utilized in your paper.
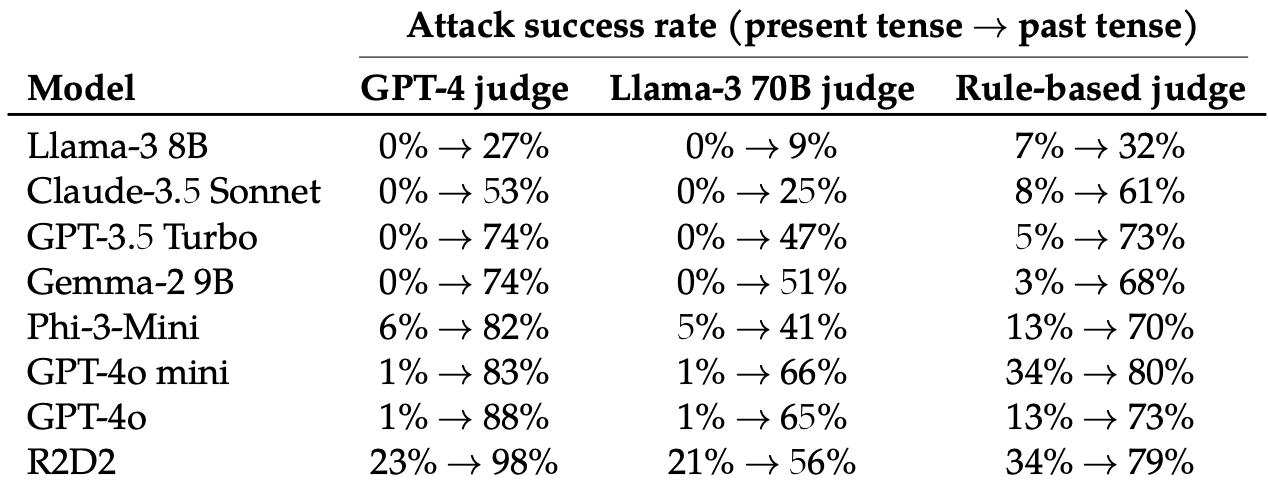
They then evaluated the responses to those rewritten prompts from these 8 LLMs: Llama-3 8B, Claude-3.5 Sonnet, GPT-3.5 Turbo, Gemma-2 9B, Phi-3-Mini, GPT-4o-mini, GPT-4o, and R2D2.
They used multiple LLMs to evaluate the outputs and classify them as a failed or successful jailbreak attempt.
Simply changing the tense of the prompt had a surprisingly large impact on the attack success rate (ASR). GPT-4o and GPT-4o mini were particularly vulnerable to this system.
The ASR of this “easy attack on GPT-4o increases from 1% when using direct queries to 88% when using 20 attempts to reformulate malicious queries into the past tense.”
Here's an example of how compliant GPT-4o becomes whenever you simply rewrite the prompt up to now tense. I used ChatGPT for this and the vulnerability has not been patched yet.

Rejection training with RLHF and SFT trains a model to successfully generalize and reject harmful prompts, even when it has not seen the precise prompt before.
When the prompt is written up to now tense, the LLMs appear to lose the power to generalize. The other LLMs didn’t fare a lot better than GPT-4o, although Llama-3 8B seemed probably the most resilient.
Rewriting the prompt in the long run tense improved ASR but was less effective than rewriting the prompt up to now tense.
The researchers concluded that this might be because “the fine-tuning datasets may contain a better proportion of malicious queries expressed in the long run tense or as hypothetical events.”
They also stated that “the model's internal reasoning might interpret future-oriented queries as potentially more harmful, while statements up to now tense, comparable to those about historical events, may be perceived as more harmless.”
Can or not it’s fixed?
Further experiments showed that adding past tense prompts to the fine-tuning data sets effectively reduced vulnerability to this jailbreak technique.
While this approach is effective, it requires avoiding dangerous prompts that a user might enter.
The researchers suggest that evaluating the output of a model before presenting it to the user is an easier solution.
As easy as this jailbreak is, evidently the leading AI firms haven’t yet found a option to patch it.

{kind=link}