
Digital colonialism refers back to the dominance of tech giants and powerful entities over the digital landscape, shaping the flow of knowledge, knowledge, and culture to serve their interests.
This dominance shouldn’t be nearly controlling digital infrastructure but in addition about influencing the narratives and knowledge structures that outline our digital age.
Digital colonialism, and now AI colonialism, are widely acknowledged terms, and institutions reminiscent of MIT have researched and written about them extensively.
Top researchers from Anthropic, Google, DeepMind, and other tech firms have openly discussed AI’s limited scope in serving people from diverse backgrounds, particularly in reference to bias in machine learning systems.
Machine learning systems fundamentally reflect the info they’re trained on – data that could be viewed as a product of our digital zeitgeist – a group of prevailing narratives, images, and concepts that dominate the web world.
But who gets to shape these informational forces? Whose voices are amplified, and whose are attenuated?
When AI learns from training data, it inherits specific worldviews that may not necessarily resonate with or represent global cultures and experiences. In addition, the controls that govern the output of generative AI tools are shaped by underlying socio-cultural vectors.
This has led developers like Anthropic to hunt democratic methods of shaping AI behavior using public views.
As Jack Clark, Anthropic’s policy chief, described a recent experiment from his company, “We’re trying to search out a strategy to develop a structure that’s developed by a complete bunch of third parties, slightly than by individuals who occur to work at a lab in San Francisco.”
Current generative AI training paradigms risk making a digital echo chamber where the identical ideas, values, and perspectives are constantly reinforced, further entrenching the dominance of those already overrepresented in the info.
As AI embeds itself into complex decision-making, from social welfare and recruitment to financial decisions and medical diagnoses, lopsided representation results in real-world biases and injustices.
Datasets are geographically and culturally situated
A recent study by the Data Provenance Initiative probed 1,800 popular datasets intended for natural language processing (NLP), a discipline of AI that focuses on language and text.
NLP is the dominant machine learning methodology behind large language models (LLMs), including ChatGPT and Meta’s Llama models.
The study reveals a Western-centric skew in language representation across datasets, with English and Western European languages defining text data.
Languages from Asian, African, and South American nations are markedly underrepresented.
Resultantly, LLMs can’t hope to accurately represent the cultural-linguistic nuances of those regions to the identical extent as Western languages.
Even when languages from the Global South look like represented, the source and dialect of the language primarily originate from North American or European creators and web sources.
The Data Provenance Initiative found that datasets largely represent English-speaking countries and the Global North. Source: Data Provenance.org.
A previous Anthropic experiment found that switching languages in models like ChatGPT still yielded Western-centric views and stereotypes in conversations.
Anthropic researchers concluded, “If a language model disproportionately represents certain opinions, it risks imposing potentially undesirable effects reminiscent of promoting hegemonic worldviews and homogenizing people’s perspectives and beliefs.”
The Data Provenance study also dissected the geographic landscape of dataset curation. Academic organizations emerge as the first drivers, contributing to 69% of the datasets, followed by industry labs (21%) and research institutions (17%).
Notably, the most important contributors are AI2 (12.3%), the University of Washington (8.9%), and Facebook AI Research (8.4%).
A separate 2020 study highlights that half of the datasets used for AI evaluation across roughly 26,000 research articles originated from as few as 12 top universities and tech firms.
Again, geographic areas reminiscent of Africa, South and Central America, and Central Asia were found to be woefully underrepresented, as viewed below.
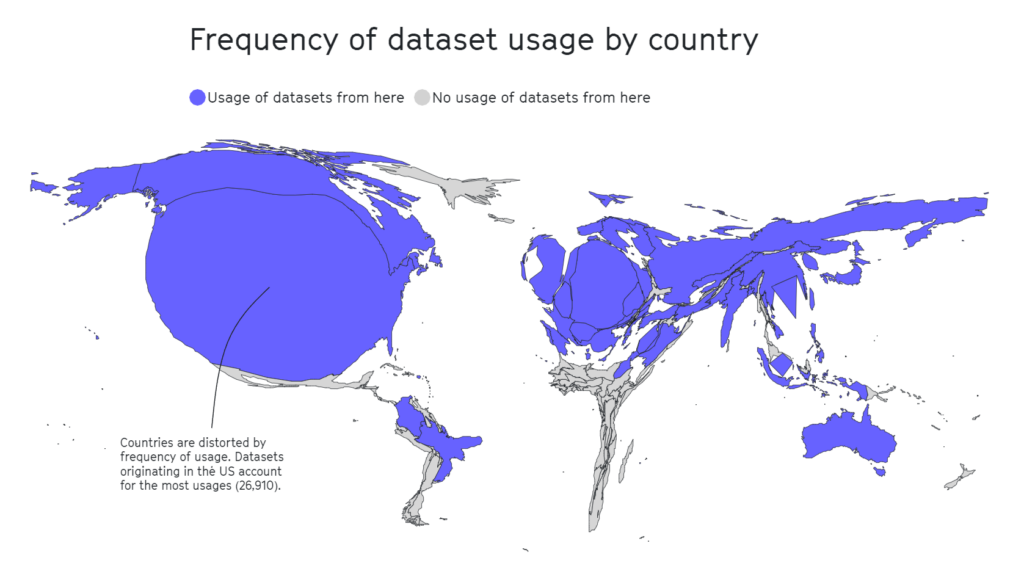 Distribution of usage of 1,933 datasets for performance benchmarking in 26,535 research papers from 2015 to 2020. Source: 2022 Internet Health Report.
Distribution of usage of 1,933 datasets for performance benchmarking in 26,535 research papers from 2015 to 2020. Source: 2022 Internet Health Report.
In other research, influential datasets like MIT’s Tiny Images or Labeled Faces within the Wild carried primarily white Western male images, with some 77.5% males and 83.5% white-skinned individuals within the case of Labeled Faces within the Wild.
In the case of Tiny Images, a 2020 evaluation by The Register found that many Tiny Images contained obscene, racist, and sexist labels.
Antonio Torralba from MIT said they weren’t aware of the labels, and the dataset was deleted. Torralba said, “It is evident that we should always have manually screened them.”
English dominates the AI ecosystem
Pascale Fung, a pc scientist and director of the Center for AI Research on the Hong Kong University of Science and Technology, discussed the issues related to hegemonic AI.
Fung refers to over 15 research papers investigating the multilingual proficiency of LLMs and consistently finding them lacking, particularly when translating English into other languages. For example, languages with non-Latin scripts, like Korean, expose LLMs’ limitations.
In addition to poor multilingual support, other studies suggest the vast majority of bias benchmarks and measures have been developed with English language models in mind.
Non-English bias benchmarks are few and much between, resulting in a big gap in our ability to evaluate and rectify bias in multilingual language models.
There are signs of improvement, reminiscent of Google’s efforts with its PaLM 2 language model and Meta’s Massively Multilingual Speech (MMS) that may discover greater than 4,000 spoken languages, 40 times greater than other approaches. However, MMS stays experimental.
Researchers are creating diverse, multilingual datasets, however the overwhelming amount of English text data, often free and straightforward to access, makes it the de facto alternative for developers.
Beyond data: structural issues in AI labor
MIT’s vast review of AI colonialism drew attention to a comparatively hidden aspect of AI development – exploitative labor practices.
AI has triggered an intense rise within the demand for data-labeling services. Companies like Appen and Sama have emerged as key players, offering the services of tagging text, images, and videos, sorting photos, and transcribing audio to feed machine learning models.
Human data specialists also manually label content types, often to sort data that incorporates illegal, illicit, or unethical content, reminiscent of descriptions of sexual abuse, harmful behavior, or other illegal activities.
While AI firms automate a few of these processes, it’s still vital to maintain ‘humans within the loop’ to make sure model accuracy and safety compliance.
The market value of this “ghost work,” as termed by anthropologist Mary Gray and social scientist Siddharth Suri, is projected to skyrocket to $13.7 billion by 2030.
Ghost work often involves exploiting low cost labor, particularly from economically vulnerable countries. Venezuela, for example, has turn into a primary source of AI-related labor because of its economic crisis.
As the country grappled with its worst peacetime economic catastrophe and astronomic inflation, a significant slice of its well-educated and internet-connected population turned to crowd-working platforms as a method of survival.
The confluence of a well-educated workforce and economic desperation made Venezuela a beautiful marketplace for data-labeling firms.
This shouldn’t be a controversial point – when MIT publishes articles with titles like “Artificial intelligence is making a latest colonial world order,” referencing scenarios reminiscent of this, it’s clear that some within the industry seek to retract the curtain on these underhand labor practices.
As MIT reports, for a lot of Venezuelans, the burgeoning AI industry has been a double-edged sword. While it provided an economic lifeline amid desperation, it also exposed people to exploitation.
Julian Posada, a PhD candidate on the University of Toronto, highlights the “huge power imbalances” in these working arrangements. The platforms dictate the foundations, leaving staff with little say and limited financial compensation despite on-the-job challenges reminiscent of exposure to disturbing content.
This dynamic is eerily harking back to historical colonial practices where empires exploited the labor of vulnerable countries, extracting profits and deserting them once the chance dwindled, actually because ‘higher value’ was available elsewhere.
Similar situations have been observed in Nairobi, Kenya, where a bunch of former content moderators working on ChatGPT lodged a petition with the Kenyan government.
They alleged “exploitative conditions” during their tenure with Sama, a US-based data annotation services company contracted by OpenAI. The petitioners claimed that they were exposed to disturbing content without adequate psychosocial support, resulting in severe mental health issues, including PTSD, depression, and anxiety.
 Kenyan lawyer Mercy Mutemi represented Kenyan staff in a lawsuit against Sama and Meta. Source: WSJ.
Kenyan lawyer Mercy Mutemi represented Kenyan staff in a lawsuit against Sama and Meta. Source: WSJ.
Documents reviewed by TIME indicated that OpenAI had signed contracts with Sama price around $200,000. These contracts involved labeling descriptions of sexual abuse, hate speech, and violence.
The impact on the mental health of the employees was profound. Mophat Okinyi, a former moderator, spoke of the psychological toll, describing how exposure to graphic content led to paranoia, isolation, and significant personal loss.
The wages for such distressing work were shockingly low – a Sama spokesperson disclosed that staff earned between $1.46 and $3.74 an hour.
Resisting digital colonialism
If the AI industry has turn into a brand new frontier of digital colonialism, then resistance is already becoming more cohesive.
Activists, often bolstered by support from AI researchers, are advocating for accountability, policy changes, and the event of technologies that prioritize the needs and rights of local communities.
Nanjala Nyabola’s Kiswahili Digital Rights Project offers an modern example of how local-scale grassroots projects can install the infrastructure required to guard communities from digital hegemony.
The project considers the hegemony of Western regulations when defining a bunch’s digital rights, as not everyone seems to be protected by the mental property, copyright, and privacy laws lots of us take with no consideration. This leaves significant proportions of the worldwide population liable to exploitation by technology firms.
Recognizing that discussions surrounding digital rights are blunted if people can’t communicate issues of their native languages, Nyabola and her team translated key digital rights and technology terms into the Kiswahili language, primarily spoken in Tanzania, Kenya, and Mozambique.
Nyabola described of the project, “During that process [of the Huduma Namba initiative], we didn’t really have the language and the tools to clarify to non-specialist or non-English language speaking communities in Kenya what the implications of the initiative were.”
In an identical grassroots project, Te Hiku Media, a non-profit radio station broadcasting primarily within the Māori language, held an unlimited database of recordings spanning a long time, lots of which echoed the voices of ancestral phrases not spoken.
Mainstream speech recognition models, just like LLMs, are likely to underdeliver when prompted in several languages or English dialects.
The Te Hiku Media collaborated with researchers and open-source technologies to coach a speech recognition model tailored for the Māori language. Māori activist Te Mihinga Komene contributed some 4,000 phrases to countless others who participated within the project.
The resulting model and data are protected under the Kaitiakitanga License – Kaitiakitanga is a Māori word with no specific English definition but is analogous to “guardian” or “custodian.”
Keoni Mahelona, a co-founder of Te Hiku Media, poignantly remarked, “Data is the last frontier of colonisation.”
These projects have inspired other indigenous and native communities under pressure from digital colonialism and other types of social upheaval, reminiscent of the Mohawk peoples in North America and Native Hawaiians.
As open-source AI becomes cheaper and easier to access, iterating and fine-tuning models using unique localized datasets should turn into simpler, enhancing cross-cultural access to the technology.
While the AI industry stays young, the time is now to bring these challenges to the fore so people can collectively evolve solutions.
Solutions may be each macro-level, in the shape of regulations, policies, and machine learning training approaches, and micro-level, in the shape of local and grassroots projects.
Together, researchers, activists, and native communities can find methods to make sure AI advantages everyone.

{kind=link}