
The US Army is dabbling with integrating AI chatbots into their strategic planning, albeit throughout the confines of a war game simulation based on the favored video game Starcraft II.
This study, led by the US Army Research Laboratory, tests the waters of employing OpenAI’s technologies, reminiscent of GPT-4 Turbo and GPT-4 Vision, to reinforce battle strategies.
Not way back, OpenAI began working on several Department of Defense projects and is collaborating with DARPA.
AI’s use on the battlefield is hotly debated, and a recent similar study on AI wargaming found that LLMs like GPT-3.5 and 4 often escalate tactics, sometimes leading to nuclear war.
This recent research used Starcraft II to simulate a battlefield scenario involving a limited variety of military units with complete visibility of the sphere.
Researchers dubbed this technique “COA-GPT” – with COA standing for the military term “Courses of Action.”
COA-GPT assumed the role of a military commander’s assistant, tasked with devising strategies to obliterate enemy forces and capture strategic points.
COA-GPT is an AI-powered decision support system that assists command and control personnel in developing Courses of Action (COAs). It utilizes LLMs constrained by predefined guidelines. Command and control personnel input mission information and COA-GPT generates potential COAs. Through an iterative process using natural language, the human operators and COA-GPT collaborate to refine and choose essentially the most suitable COA for the mission objectives. Source: ArXiv.
Traditional COA is notoriously slow and labor-intensive, but not COA-GPT. Decisions are made in seconds, iteratively integrating military human feedback into the AI’s learning process.
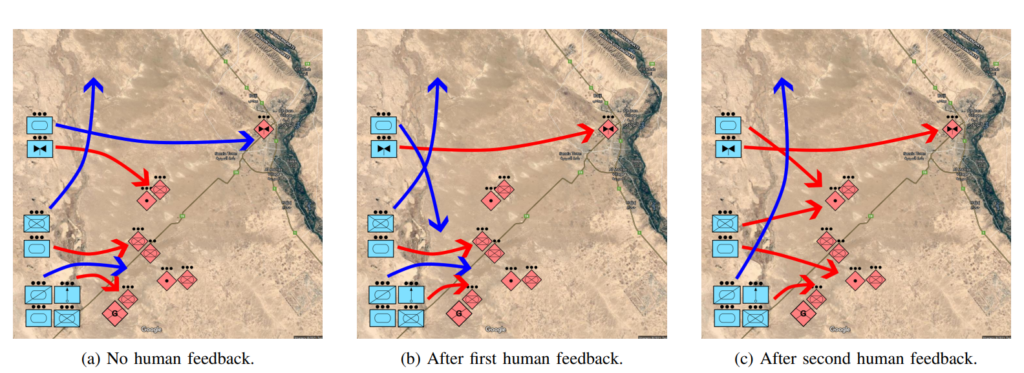 Illustrates the iterative means of developing Courses of Action (COAs) with human input. In (a), COA-GPT generates an initial COA without human guidance, displaying force movements (blue arrows) across bridges and engagement directives (red arrows) against hostile units. Panel (b) shows the COA after a human commander adjusts it, specifying that friendly aviation forces should directly engage hostile aviation. Finally, (c) demonstrates further COA refinement, with forces splitting to handle each enemy artilleries and reconnaissance units receiving orders to advance to the northern bridge. Source: ArXiv.
Illustrates the iterative means of developing Courses of Action (COAs) with human input. In (a), COA-GPT generates an initial COA without human guidance, displaying force movements (blue arrows) across bridges and engagement directives (red arrows) against hostile units. Panel (b) shows the COA after a human commander adjusts it, specifying that friendly aviation forces should directly engage hostile aviation. Finally, (c) demonstrates further COA refinement, with forces splitting to handle each enemy artilleries and reconnaissance units receiving orders to advance to the northern bridge. Source: ArXiv.
Researchers emphasized that COA-GPT merely augments human decision-making somewhat than replacing it.
COA-GPT excels other methods, but there’s a value
COA-GPT demonstrated superior performance to existing methods, outpaced existing methods in generating strategic COAs, and will adapt to real-time feedback.
However, there have been flaws. Most notably, COA-GPT incurred higher casualties in accomplishing mission objectives.
The study states, “We observe that the COA-GPT and COA-GPT-V, even when enhanced with human feedback exhibits higher friendly force casualties in comparison with other baselines.”
Does this deter the researchers? Seemingly not.
The study says, “In conclusion, COA-GPT represents a transformative approach in military C2 operations, facilitating faster, more agile decision-making and maintaining a strategic edge in modern warfare.”
You’d must say it’s worrying that an AI system that caused more friendly fire casualties than expected is defined as a “transformative approach.”
This comes after the Department of Defense created a generative AI task force last yr. The DOD has already identified quite a few avenues for exploration, yet concerns concerning the technology’s readiness and ethical implications loom.
For example, who’s responsible when military AI applications go fallacious? The developers? The person in charge? Or someone further down the chain?
It’s unproven, and let’s hope it stays that way.

{kind=link}