
Keeping up with an industry as fast-moving as AI is a large challenge. Until an AI can do it for you, here's a handy roundup of the newest stories from the world of machine learning, in addition to notable research and experiments that we haven't covered alone.
Last week, Midjourney, built AI startup Image (and shortly video) Generators, has made a small, surprising change to its Terms of Service related to the corporate's IP dispute policy. It served primarily to exchange humorous formulations with more legal clauses, undoubtedly based on case law. The change will also be seen as an indication of Midjourney's belief that AI providers like themselves will emerge victorious from the legal disputes with developers whose works include training data from providers.
Changing Midjourney's Terms of Use.
Generative AI models like Midjourney's are trained on an unlimited variety of examples – e.g. B. Images and text – which often come from public web sites and repositories on the Internet. Providers claim This fair use, the legal doctrine that permits the usage of copyrighted works to supply a secondary creation so long as it’s transformative, protects it in the case of training models. But not all developers agree – especially given a growing variety of studies showing that models can and do “give out” training data.
Some providers have taken a proactive approach by moving into licensing agreements with content creators and implementing opt-out policies for training datasets. Others have promised that customers who grow to be involved in a copyright dispute over their use of a vendor's GenAI tools is not going to should pay legal fees.
Midjourney just isn’t one in every of the proactive ones.
On the contrary, Midjourney was a bit daring in its use of copyrighted works at one point Maintenance an inventory of 1000’s of artists – including illustrators and designers from major brands like Hasbro and Nintendo – whose work was or could be used to coach Midjourney's models. A study shows compelling evidence that Midjourney also used TV shows and movie franchises in its training data, from “Toy Story” to “Star Wars” to “Dune” to “Avengers.”
Now there may be a scenario wherein court decisions ultimately turn into in favor of Midjourney. If the judicial system decides that fair use applies, nothing will stop the startup from continuing as usual, scraping and training old and recent copyrighted data.
But it looks like a dangerous bet.
Midjourney is in full swing in the intervening time allegedly achieved sales of around $200 million with no penny of outdoor investment. However, lawyers are expensive. And if it's decided that fair use doesn't apply in Midjourney's case, it will decimate the corporate overnight.
No reward without risk, right?
Here are another notable AI stories from recent days:
AI-powered promoting attracts the fallacious form of attention: YouTubers took to Instagram to attack a director whose industrial reused the work of one other (way more difficult and impressive) without attribution.
EU authorities are drawing attention to AI platforms ahead of elections: They're asking the largest tech firms to clarify their approach to stopping voter fraud.
Google Deepmind wants your co-op gaming partner to be its AI: By training an agent through hours of 3D gaming, they can perform easy tasks in natural language.
The problem with benchmarks: Many, many AI vendors claim that their models have outperformed or outperformed the competition by some objective metric. But the metrics they use are sometimes flawed.
AI2 raises $200 million: AI2 Incubator, a by-product of the nonprofit Allen Institute for AI, has secured a windfall of $200 million in computing power that startups going through its program can use to speed up early development.
India requires government approval for AI after which rolls it back: The Indian government appears unable to make a decision what level of regulation is acceptable for the AI industry.
Anthropic launches recent models: AI startup Anthropic has launched a brand new model family, Claude 3, which is alleged to compete with OpenAI's GPT-4. We put the flagship model (Claude 3 Opus) to the test and located it impressive – but additionally lacking in areas corresponding to current events.
Political deepfakes: A study by the Center for Countering Digital Hate (CCDH), a British non-profit organization, examines the growing amount of AI-generated disinformation – particularly election-related deepfake images – on X (formerly Twitter) over the past yr.
OpenAI vs Musk: OpenAI says it intends to follow all claims made by Elon Musk, CEO of and success.
Review of Rufus: Last month, Amazon announced that it will be launching a brand new AI-powered chatbot, Rufus, within the Amazon Shopping app for Android and iOS. We got early access – and were quickly dissatisfied by the dearth of things Rufus can do (and do well).
More machine learning
Molecules! How do you’re employed? AI models have helped us understand and predict molecular dynamics, conformation, and other facets of the nanoscopic world which may otherwise require expensive and complicated methods to check. Of course, this still must be verified, but things like AlphaFold are changing the sphere rapidly.
Microsoft has a brand new model called ViSNet, with the aim of predicting so-called structure-activity relationships, complex relationships between molecules and biological activity. It's still quite experimental and definitely only for researchers, nevertheless it's at all times great to see difficult scientific problems being solved using cutting-edge technological means.
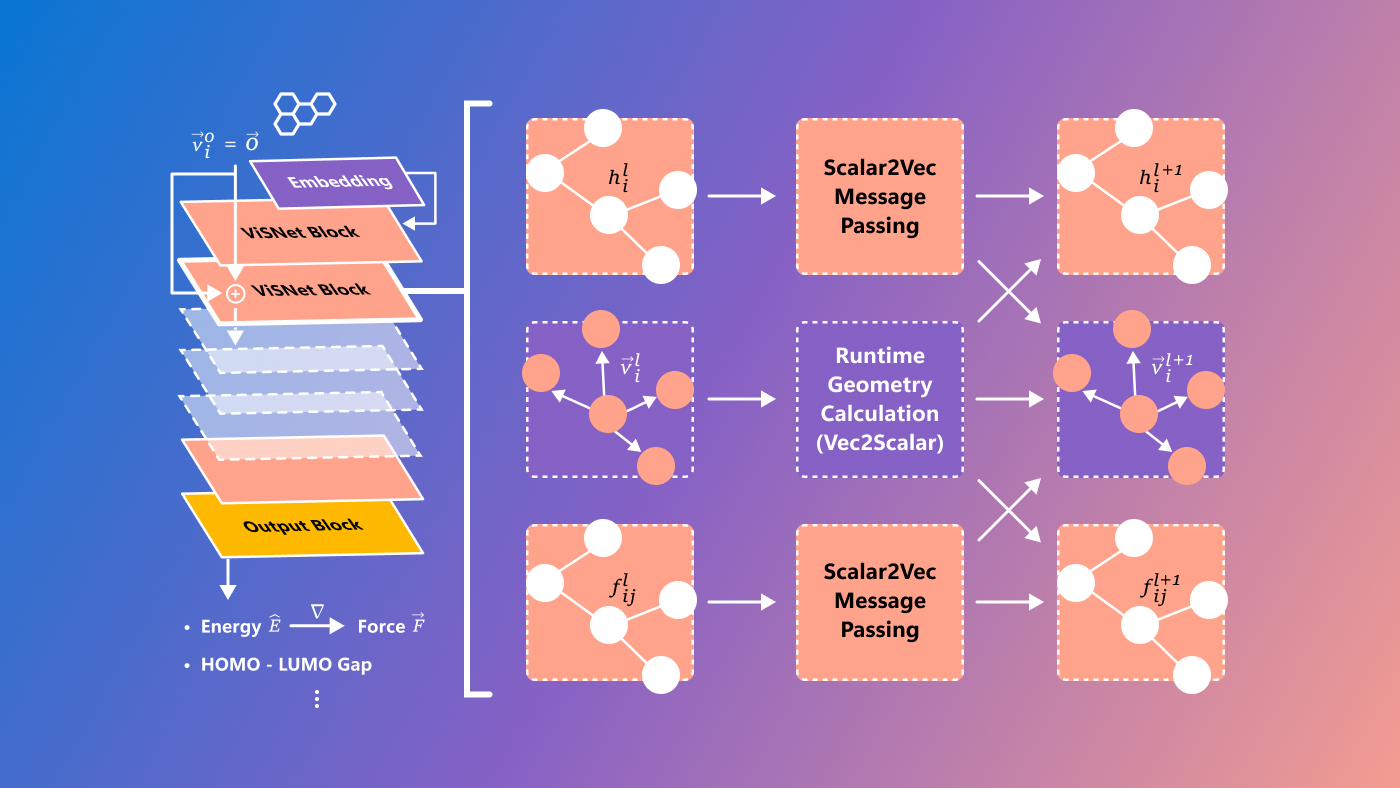
Photo credit: Microsoft
Researchers on the University of Manchester are investigating this specifically Identification and prediction of COVID-19 variantsless through pure structures like ViSNet and more through evaluation of the very large genetic data sets related to coronavirus evolution.
“The unprecedented amount of genetic data generated through the pandemic requires improvements in our methods to investigate it thoroughly,” said lead researcher Thomas House. His colleague Roberto Cahuantzi added: “Our evaluation serves as a proof of concept and demonstrates the potential use of machine learning methods as an alert tool for the early detection of emerging major variants.”
AI may also design molecules, and quite a lot of researchers have done so signed an initiative We demand safety and ethics on this area. However, as David Baker (one in every of the world's leading computational biophysicists) states: “The potential advantages of protein design currently far outweigh the risks.” Well, as an AI protein designer, he says so. Still, we should be wary of regulations, that miss the purpose and hinder legitimate research while allowing bad actors freedom.
Atmospheric researchers on the University of Washington have made an interesting claim based on an AI evaluation of 25 years of satellite images over Turkmenistan. Essentially, the widely accepted view that the economic turmoil following the autumn of the Soviet Union led to lower emissions will not be true – In fact, the alternative could have occurred.
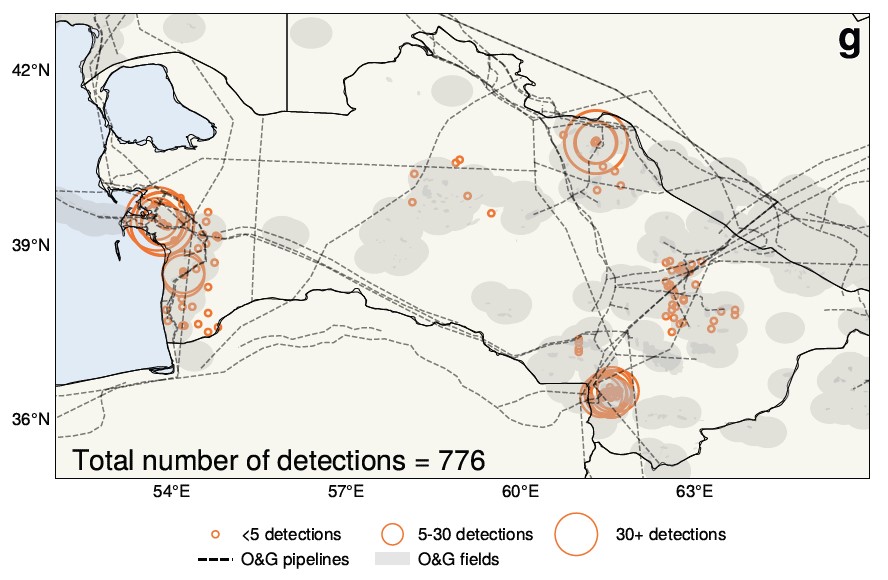
AI helped find and measure the methane leaks shown here.
“We find that, surprisingly, the collapse of the Soviet Union appears to guide to a rise in methane emissions,” said UW professor Alex Turner. The large amounts of knowledge and the dearth of time to sift through them made the subject a natural goal for AI, resulting in this unexpected turn of events.
Large language models are largely trained on English source data, but this may affect greater than just their ability to make use of other languages. EPFL researchers examined LlaMa-2's “latent language” and located that the model appears to make use of English internally, even when translating between French and Chinese. However, the researchers consider that that is greater than a delayed translation process, and the model actually did structured his entire conceptual latent space around English terms and representations. Is it vital? Probably. We should diversify their data sets anyway.

{kind=link}