
Keeping up with an industry as fast-moving as AI is a big challenge. Until an AI can do it for you, here's a handy roundup of the newest stories from the world of machine learning, in addition to notable research and experiments that we haven't covered alone.
This week in AI, I would like to concentrate on label and annotation startups – startups like Scale AI allegedly in talks to boost $13 billion in recent funding. Annotation and annotation platforms may not get the eye that flashy recent generative AI models like OpenAI's Sora do. But they’re essential. Without them, modern AI models would probably not exist.
The data that many models train on must be labeled. Why? Labels or tags help models understand and interpret data in the course of the training process. For example, labels for training a picture recognition model could take the shape of markers around objects: “Bounding box” or captions that check with any person, place or object depicted in a picture.
The accuracy and quality of labels significantly impact the performance – and reliability – of the trained models. And annotation is a large undertaking, requiring 1000’s to thousands and thousands of labels for the larger and more complex datasets in use.
So one might assume that data annotators could be treated well, paid a living wage, and given the identical advantages enjoyed by the engineers who construct the models themselves. But often the other is true – a results of the brutal working conditions that many annotation and labeling startups encourage.
Billion-dollar firms like OpenAI have relied on it Commentators in third world countries were paid just a couple of dollars an hour. Some of those annotators are exposed to extremely disturbing content comparable to graphic images, but will not be supplied with break day (as they’re typically contractors) or access to mental health resources.
An excellent one Piece in NY Mag notably reveals Scale AI recruiting commentators in countries as far-off as Nairobi and Kenya. Some of the tasks on Scale AI take labelers multiple eight-hour workdays—with no breaks—and price as little as $10. And these employees are beholden to the whims of the platform. Annotators sometimes go unemployed for long periods of time, or are summarily excluded from Scale AI, as was the case with contractors in Thailand, Vietnam, Poland, and Pakistan recently.
Some annotation and tagging platforms claim to supply “fair trade” work. They've actually made it a core a part of their branding. But as Kate Kaye of MIT Tech Review Remarksthere aren’t any regulations, only weak industry standards for what ethical labeling means – and the definitions of the businesses themselves vary widely.
So what to do? Unless there’s a serious technological breakthrough, the necessity to annotate and label data for AI training won’t go away. We can hope that the platforms regulate themselves, however the more realistic solution appears to be policymaking. This is a fragile matter in itself – but in my view it’s one of the best probability we’ve got to alter things for the higher. Or at the least start with it.
Here are another notable AI stories from recent days:
-
- OpenAI builds a voice cloner: OpenAI previews a brand new AI-powered tool called Voice Engine that permits users to clone a voice from a 15-second recording of an individual speaking. However, the corporate chooses to not release it generally (yet) on account of the danger of misuse and misuse.
- Amazon doubles down on Anthropic: Amazon has invested one other $2.75 billion in growing AI company Anthropic, following up on an option left open in September last yr.
- Google.org is launching an accelerator: Google.org, the nonprofit wing of Google, is launching a brand new, $20 million, six-month program to assist nonprofits develop technologies that use generative AI.
- A brand new model architecture: AI startup AI21 Labs has released Jamba, a generative AI model that uses a novel recent model architecture – state space models or SSMs – to enhance efficiency.
- Databricks introduces DBRX: In other model news this week, Databricks released DBRX, a generative AI model much like OpenAI's GPT series and Google's Gemini. The company claims to realize state-of-the-art results on various popular AI benchmarks, including several measurement justifications.
- Uber Eats and UK AI regulation: Natasha writes about how an Uber Eats courier's battle against AI bias shows that justice under the UK's AI regulations is difficult won.
- EU guidance on election security: The European Union published on Tuesday draft election security guidelines aimed toward the population two dozen Platforms regulated under the Digital Services Act, including guidelines to stop the spread of generative AI-based disinformation (also often called political deepfakes) through content advice algorithms.
- Grok is updated: X's Grok chatbot will soon receive an updated base model, Grok-1.5 – at the identical time that every one Premium subscribers will receive (Grok was previously exclusive to X Premium+ customers.)
- Adobe expands Firefly: This week Adobe introduced Firefly Services, a set of greater than 20 recent generative and inventive APIs, tools and services. It also introduced custom models, allowing firms to optimize Firefly models based on their assets – a part of Adobe's recent GenStudio suite.
More machine learning
What's the weather like? AI is increasingly capable of let you know this. I noticed some efforts in hourly, weekly and century forecasting a couple of months ago, but like all the things related to AI, this area is evolving quickly. The teams behind MetNet-3 and GraphCast have published a paper describing a brand new system called SEEDSfor Scalable Ensemble Envelope Diffusion Sampler.
Animation showing how more forecasts result in a more even distribution of weather forecasts.
SEEDS uses diffusion to generate “ensembles” of plausible weather outcomes for an area based on the inputs (radar readings or orbital imagery perhaps) much faster than physics-based models. With a bigger ensemble number, they will cover more edge cases (e.g. an event that only occurs in one in every of 100 possible scenarios) and behave more confidently in additional likely situations.
Fujitsu also hopes to raised understand nature Applying AI image processing techniques to underwater images and lidar data collected by autonomous underwater vehicles. Improving image quality allows other, less demanding processes (like 3D conversion) to work higher with the goal data.
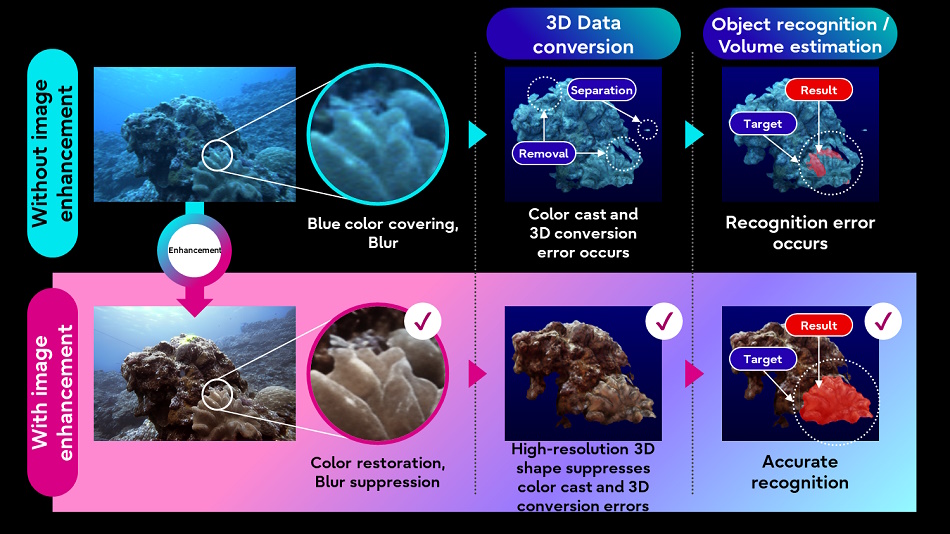
Photo credit: Fujitsu
The idea is to create a “digital twin” of water bodies that might help simulate and predict recent developments. We're still a good distance from that, but you may have to begin somewhere.
When it involves LLMs, researchers have found that they mimic intelligence through an excellent simpler method than expected: linear functions. To be honest, the mathematics is a mystery to me (vector material in lots of dimensions), but this text at MIT makes it pretty clear that the recall mechanism of those models is pretty… easy.
Although these models are really complicated, nonlinear functions which can be trained on loads of data and are very obscure, sometimes really easy mechanisms work in them. This is an example of that,” said co-lead writer Evan Hernandez. If you’re more tech savvy, Check out the paper here.
One way these models can fail is that they don't understand context or feedback. Even a very capable LLM may not understand in case you tell them that your name is pronounced a certain way because they don't actually know or understand anything. In cases where this is likely to be vital, comparable to human-robot interactions, having the robot act this fashion could put people off.
Disney Research has long been fascinated by automated character interactions Pronunciation of this name and reuse of paper only appeared a while ago. It seems obvious, but extracting the phonemes when someone introduces themselves and encoding those, relatively than simply the written name, is a great approach.

Photo credit: Disney Research
Finally, as AI and search increasingly overlap, it's price reevaluating how these tools are used and whether this unholy connection introduces recent risks. Safiya Umoja Noble has been a very important voice in AI and search ethics for years and her opinions are all the time insightful. She did a pleasant interview with the UCLA news team about how their work has evolved and why we must remain stone-cold about bias and bad habits in search.

{kind=link}